Combining Self-Supervised Learning and Imitation
for Vision-Based Rope Manipulation
Ashvin Nair*, Dian Chen*, Pulkit Agrawal*, Phillip Isola, Pieter Abbeel, Jitendra Malik, Sergey Levine
- *Equal Contribution
Abstract
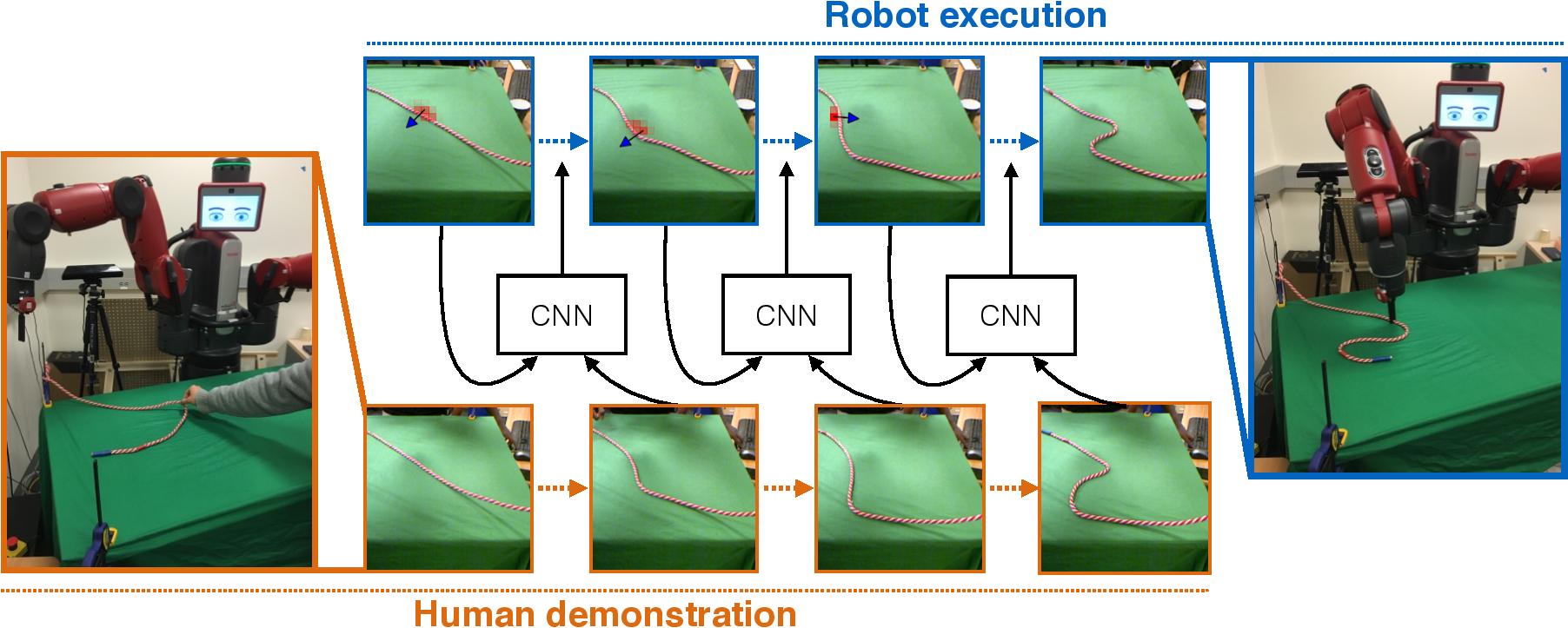
We present a system where a robot takes as input a sequence of images of a human manipulating a rope from an initial to goal configuration, and outputs a sequence of actions that can reproduce the human demonstration, using only monocular images as input. To perform this task, the robot learns a pixel-level inverse dynamics model of rope manipulation directly from images in a self-supervised manner, using more than 30K interactions with the rope collected autonomously by the robot. The human demonstration provides a high-level plan of what to do and the low-level inverse model is used to execute the plan. We show that by combining the high and low-level plans, the robot can successfully manipulate a rope into a variety of target shapes using only a sequence of human-provided images for direction.
Paper
The paper is available at: [pdf]
Data
Data (60K+ actions) used for training the inverse dynamics model is available here with an included iPython notebook showing how to load and align the data. Instructions on how to use our validation set for evaluating the accuracy of the learnt model are included in an iPython notebook here.
Video
Robot's Rope Manipulation Skills
Generalization Experiments
Architecture
The network architecture used is shown below and explained in the paper.
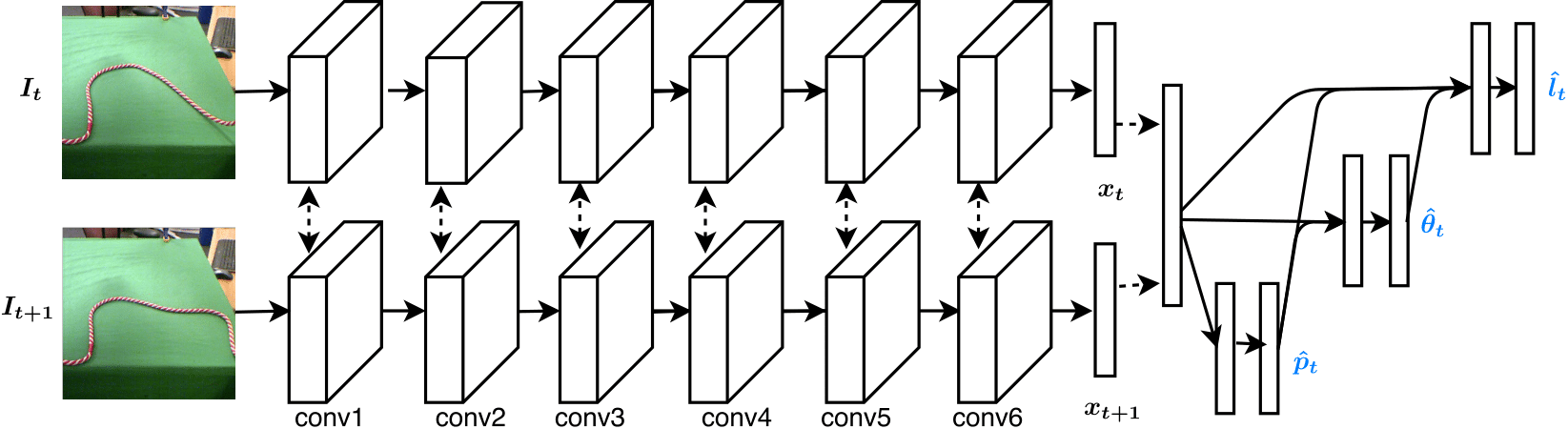
The classification output for the three variables is done with an autoregressive architecture. For example, in the model we evaluated on the robot, we first output a classification prediction for p (pixel), then sample the top prediction and feed it into the next prediction (theta), and so on for length, as shown in the image above. Below, we include the test accuracy of the top prediction for each variable and for different network architectures trained on the publicly available data of 30K actions.
| Prediction Ordering | P Accuracy | T Accuracy | L Accuracy |
| None (Independent) | 12% | 13% | 20% |
| P -> T -> L | 10% | 16% | 29% |
| L -> T -> P | 14% | 13% | 22% |
Link to videos
All videos above can be accessed here.
Link to prior work
Our previous project on model learning and large-scale data collection can be viewed here.
Website Template
The template for this website has been adopted from Carl Doersch.
Contact
For comments/questions, contact Pulkit Agrawal